19 OCR (Texterkennung)
 Aufgabe: OCR
Aufgabe: OCR
19.1 Beschreibung
Die Aufgabe OCR (Optical Character Recognition / Optische Zeichenerkennung) wandelt gescannte Dokumente oder Bild-PDFs in durchsuchbare PDFs um. Nach der Verarbeitung kann der Text im PDF markiert, kopiert und durchsucht werden.
Typische Anwendungsfälle
- Archivierung: Gescannte Dokumente durchsuchbar machen
- Datenextraktion: Text aus gescannten Rechnungen für die weitere Verarbeitung extrahieren
- Compliance: Dokumente für die Volltextsuche in Dokumentenmanagementsystemen vorbereiten
- Barrierefreiheit: PDFs für Screenreader zugänglich machen
Wichtig: Diese Aufgabe erzeugt eine neue Datei im konfigurierten Zielordner. Die Originaldatei bleibt unverändert. Die im aktuellen Profil enthaltenen weiteren Aufgaben beziehen sich alle auf die Originaldatei. Das durch OCR erzeugte durchsuchbare PDF muss bei Bedarf mit einem separaten Profil weiterverarbeitet werden, das den entsprechenden Ausgabeordner überwacht.
19.2 Allgemeine Einstellungen
Aktiviert
Aktivieren Sie diese Option, damit die Aufgabe bei passenden PDF-Dateien ausgeführt wird. Deaktivierte Aufgaben werden übersprungen.
19.3 Sprache
Primäre Sprache
Wählen Sie die Hauptsprache des zu erkennenden Textes. Die korrekte Sprachwahl verbessert die Erkennungsgenauigkeit erheblich.
Verfügbare Sprachen: Über 100 Sprachen, darunter: - Deutsch (German Best) - Englisch (English Best) - Französisch, Spanisch, Italienisch - Und viele weitere
Hinweis: Nicht installierte Sprachen können über Extras → Sprachen installieren heruntergeladen werden.
Sekundäre Sprache verwenden
Aktivieren Sie diese Option, wenn Dokumente Text in zwei Sprachen enthalten (z.B. deutsch-englische Verträge).
Sekundäre Sprache
Wählen Sie die zweite im Dokument vorkommende Sprache.
19.4 DPI-Einstellung (Auflösung)
Die DPI-Einstellung (Dots Per Inch) beeinflusst die Qualität der Texterkennung und die Größe der Ausgabedatei.
Optimiert
Das Programm wählt automatisch eine optimale DPI-Einstellung basierend auf dem Dokumentinhalt.
Basierend auf Bildern
Die DPI wird basierend auf der Auflösung der im PDF enthaltenen Bilder bestimmt. Dies ist die Standard-Einstellung.
Benutzerdefiniert
Sie können einen festen DPI-Wert festlegen:
| DPI |
Verwendung |
| 96-150 |
Schnelle Verarbeitung, geringere Qualität |
| 175-225 |
Gute Balance zwischen Qualität und Geschwindigkeit (empfohlen) |
| 300 |
Hohe Qualität, längere Verarbeitung |
| 600-1200 |
Maximale Qualität, nur für spezielle Anforderungen |
19.5 Bildoptimierung
Seitenorientierung automatisch korrigieren
Erkennt und korrigiert die Seitenorientierung (0°, 90°, 180°, 270°) vor der OCR-Verarbeitung. Diese Option ist besonders nützlich für Dokumente aus Scannern, die Seiten im Hoch- und Querformat gemischt einziehen. Die Korrektur wird nur bei hoher Erkennungssicherheit angewendet.
Hinweis: Diese Option ist standardmäßig deaktiviert. Aktivieren Sie sie, wenn Sie regelmäßig falsch gedrehte Scans verarbeiten.
Schräglage korrigieren (Deskew)
Korrigiert leicht schräg gescannte Dokumente automatisch. Verbessert die Erkennung bei nicht exakt ausgerichteten Scans.
Schärfen
Erhöht die Schärfe von Bildern vor der Texterkennung. Hilfreich bei leicht unscharfen Scans.
Kontrast erhöhen
Verbessert den Kontrast zwischen Text und Hintergrund. Nützlich bei verblasstem oder schwachem Text.
PDF-Inhalt vorher in Bilder konvertieren
Wandelt den gesamten PDF-Inhalt vor der OCR in Bilder um. Aktivieren Sie diese Option bei PDFs, die sowohl Text als auch Bilder mit Text enthalten.
Niedrige Auflösungen hochskalieren
Skaliert Bilder mit niedriger Auflösung automatisch hoch, um die Erkennungsgenauigkeit zu verbessern.
19.6 Umgang mit Dateien, die bereits Text enthalten
Legen Sie fest, wie mit PDFs verfahren werden soll, die bereits durchsuchbaren Text enthalten:
| Option |
Beschreibung |
| Ignorieren |
Das PDF wird nicht verarbeitet (Standard) |
| Trotzdem verarbeiten |
OCR wird durchgeführt, auch wenn Text vorhanden ist |
| Nur in das Zielverzeichnis kopieren |
Das PDF wird ohne OCR in den Zielordner kopiert |
Empfehlung: Belassen Sie die Einstellung auf “Ignorieren”, es sei denn, Sie haben einen speziellen Grund für eine andere Wahl.
19.7 Zeichenbeschränkung
Zeichen einschränken
Aktivieren Sie diese Option, um die Erkennung auf bestimmte Zeichen zu beschränken. Dies kann die Genauigkeit bei spezialisierten Dokumenten verbessern.
Nur folgende Zeichen erlauben (Whitelist)
Geben Sie die Zeichen an, die erkannt werden sollen. Alle anderen werden ignoriert.
Standardzeichen: ABCDEFGHIJKLMNOPQRSTUVWXYZÄÖÜßabcdefghijklmnopqrstuvwxyzäöü0123456789.,-?!
Folgende Zeichen ausschließen (Blacklist)
Geben Sie Zeichen an, die nicht erkannt werden sollen.
Anwendungsfall: Bei der Erkennung von Artikelnummern, die nur aus Zahlen und Buchstaben bestehen, können Sonderzeichen ausgeschlossen werden.
19.8 Verarbeitung
Multithreading
Aktiviert die parallele Verarbeitung mehrerer Seiten. Beschleunigt das OCR auf Systemen mit mehreren Prozessorkernen erheblich.
Empfehlung: Aktiviert lassen, es sei denn, es treten Stabilitätsprobleme auf.
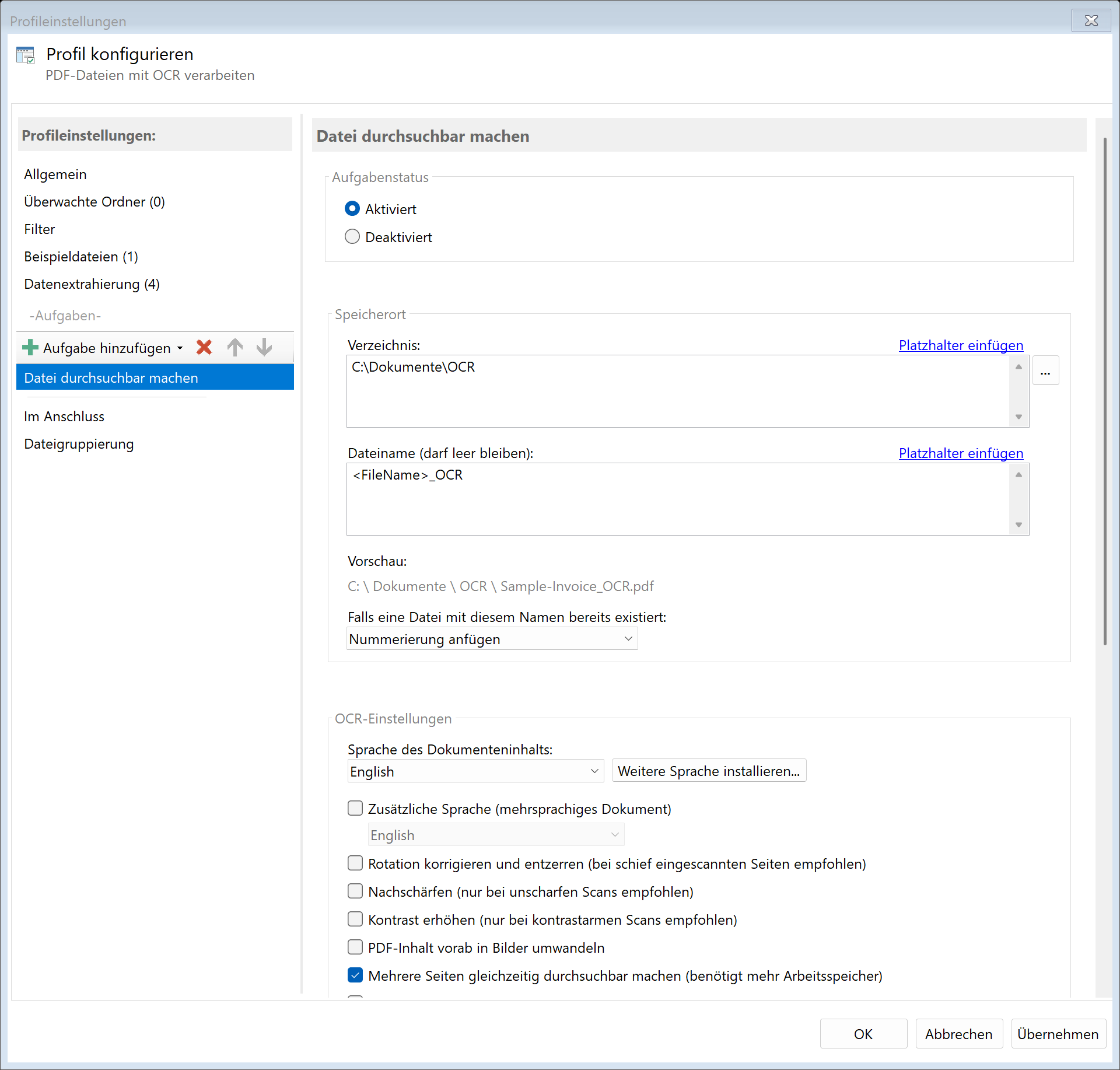
19.9 Speicherort
Verzeichnis
Geben Sie das Zielverzeichnis für die durchsuchbaren PDFs an.
Hinweis: Es wird empfohlen, für jeden Verarbeitungsschritt einen eigenen Ordner zu verwenden, um eine klare Trennung zu gewährleisten.
Dateiname
Legen Sie den Namen für die Ausgabedatei fest. Sie können: - Das Feld leer lassen (Originalname wird verwendet) - Einen festen Namen eingeben - Platzhalter für dynamische Namen verwenden
Beispiele:
| Eingabe |
Ergebnis |
| (leer) |
Scan001.pdf (Originalname) |
<FileName>_OCR |
Scan001_OCR.pdf |
<TodaysYear4>-<TodaysMonth>-<TodaysDay>_<FileName> |
2024-12-15_Scan001.pdf |
Namenskollisionen
Wählen Sie, was passieren soll, wenn bereits eine Datei mit dem Zielnamen existiert:
| Option |
Beschreibung |
| Überschreiben |
Die vorhandene Datei wird ersetzt |
| Nummerierung anfügen |
Fügt eine Nummer an |
| Datum anfügen |
Fügt das Verarbeitungsdatum an |
| Datum und Uhrzeit anfügen |
Fügt Datum und Uhrzeit an |
| Vorgang abbrechen |
Die OCR wird nicht durchgeführt |
19.10 Dateidatum
Erstellungs- und Änderungsdatum anpassen
Optional können Sie das Dateidatum der Ausgabedatei ändern:
| Option |
Beschreibung |
| Nicht ändern |
Die Datei erhält automatisch das aktuelle Datum |
| Erstellungsdatum der Originaldatei |
Übernimmt das ursprüngliche Erstellungsdatum |
| Änderungsdatum der Originaldatei |
Übernimmt das Änderungsdatum |
| PDF-Erstellungsdatum |
Datum aus den PDF-Metadaten |
| Extrahiertes Datum |
Ein mit einer Extrahierungsregel gewonnenes Datum |
| Aktuelles Datum |
Setzt das heutige Datum |
19.11 Im Anschluss
Externes Programm aufrufen
Nach der OCR kann automatisch ein externes Programm gestartet werden.
Programm: Pfad zur ausführbaren Datei
Parameter: Kommandozeilenparameter. Verfügbare Platzhalter: - <PathIncludingFilename> - Vollständiger Pfad der OCR-Datei - <ParentDirectory> - Pfad des Elternordners - <Filename> - Dateiname der OCR-Datei
19.12 Beispiel: Gescannte Rechnungen durchsuchbar machen
Ausgangssituation
Ihr Scanner erstellt Bild-PDFs ohne durchsuchbaren Text. Diese sollen automatisch per OCR verarbeitet werden, damit Sie später nach Rechnungsnummern oder Beträgen suchen können.
Konfiguration
- Aktiviert: Ja
- Primäre Sprache: German Best
- DPI-Einstellung: Basierend auf Bildern
- Schräglage korrigieren: Ja
- Umgang mit Dateien mit Text: Nur in das Zielverzeichnis kopieren
- Verzeichnis:
D:\Archiv\OCR
- Dateiname:
<FileName>
- Bei Namenskollision: Nummerierung anfügen
Ergebnis
| Originaldatei |
OCR-Datei |
C:\Scanner\Scan001.pdf (Bild) |
D:\Archiv\OCR\Scan001.pdf (durchsuchbar) |
19.13 Beispiel: Mehrsprachige Dokumente verarbeiten
Ausgangssituation
Sie verarbeiten internationale Verträge, die sowohl deutschen als auch englischen Text enthalten.
Konfiguration
- Primäre Sprache: German Best
- Sekundäre Sprache verwenden: Ja
- Sekundäre Sprache: English Best
- DPI-Einstellung: 225 (Benutzerdefiniert)
- Schärfen: Ja
Hinweis
Die Verwendung von zwei Sprachen erhöht die Verarbeitungszeit, verbessert aber die Erkennungsgenauigkeit bei gemischtsprachigen Dokumenten erheblich.
19.7 Tipps und Hinweise
Weiterverarbeitung des OCR-PDFs
Das erzeugte durchsuchbare PDF befindet sich im konfigurierten Zielordner. Um es weiter zu verarbeiten (z.B. Datenextraktion, Umbenennung, E-Mail-Versand), erstellen Sie ein separates Profil, das diesen Zielordner überwacht.
Sprachen installieren
Nicht alle OCR-Sprachen sind standardmäßig installiert. Verwenden Sie Extras → Sprachen installieren, um zusätzliche Sprachen herunterzuladen.
Erkennungsqualität verbessern
Wenn die Texterkennung unbefriedigend ist: 1. Erhöhen Sie die DPI-Einstellung 2. Aktivieren Sie Bildoptimierungen (Schärfen, Kontrast, Deskew) 3. Stellen Sie sicher, dass die korrekte Sprache ausgewählt ist 4. Bei Problemen mit bestimmten Zeichen: Verwenden Sie die Zeichenbeschränkung
Verarbeitungszeit
Die OCR-Verarbeitung ist rechenintensiv. Faktoren, die die Geschwindigkeit beeinflussen: - Seitenzahl des Dokuments - Gewählte DPI-Einstellung - Aktivierte Bildoptimierungen - Verwendung von zwei Sprachen - Verfügbare Prozessorleistung
Qualität vs. Geschwindigkeit
| Priorität |
Empfohlene Einstellungen |
| Geschwindigkeit |
Niedrige DPI (150), keine Bildoptimierung |
| Balance |
DPI 225, Schräglage korrigieren (Standard) |
| Qualität |
DPI 300+, alle Bildoptimierungen aktiviert |
Bereits durchsuchbare PDFs
Wenn Sie “Ignorieren” für Dateien mit Text wählen, werden bereits durchsuchbare PDFs nicht erneut verarbeitet. Dies spart Zeit und verhindert Qualitätsverlust durch mehrfache Verarbeitung.
Passwortgeschützte PDFs
Passwortgeschützte PDFs können verarbeitet werden, wenn das Passwort in der Passwortliste (Programmoptionen) oder im Profil hinterlegt ist und das Extrahieren von Inhalten erlaubt ist.